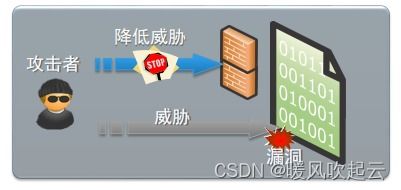


反爬软件的主要功能包括:
IP封禁:通过识别和封禁恶意IP,防止爬虫程序对网站进行大规模攻击。
请求频率限制:限制爬虫程序在一定时间内的请求次数,降低对网站资源的消耗。
验证码识别:通过验证码识别技术,防止爬虫程序绕过验证码限制。
行为分析:通过分析用户行为,识别和阻止异常访问。
用户代理检测:识别和阻止非正常用户代理访问。

尽管反爬软件在保护网站数据安全方面发挥着重要作用,但同时也存在一定的安全风险:
数据泄露:反爬软件在识别和封禁爬虫程序的过程中,可能会误封正常用户,导致数据泄露。
恶意攻击:黑客可能会利用反爬软件的漏洞,对网站进行攻击。
隐私侵犯:反爬软件在收集用户行为数据时,可能会侵犯用户隐私。
为了提高反爬软件的安全性,可以从以下几个方面入手:
加强技术研发:不断优化反爬算法,提高识别和封禁爬虫程序的能力。
完善安全策略:制定合理的安全策略,避免误封正常用户。
加强数据保护:对用户行为数据进行加密存储,防止数据泄露。
提高透明度:公开反爬软件的原理和策略,接受用户监督。

随着数据安全意识的不断提高,反爬软件在数据安全领域的应用前景十分广阔。未来,反爬软件将朝着以下方向发展:
智能化:通过人工智能技术,实现更精准的爬虫识别和封禁。
多样化:针对不同类型的网站和业务需求,开发定制化的反爬软件。
跨平台:支持多种操作系统和浏览器,提高反爬软件的兼容性。
反爬软件作为守护网站数据安全的重要防线,在互联网时代发挥着越来越重要的作用。面对数据安全挑战,我们需要不断加强反爬软件的研发和应用,为网站数据安全保驾护航。